n8n과 노션으로 구축하는 RAG 기반 사내 AI 챗봇 가이드
PainPoint
자사에서는 업계 특성상 임직원의 입/퇴사가 잦은 편이고, 이로 인한 자세한 온보딩 여력이 되지 않는다. 그로인한 다양한 임직원의 문의는 인사팀의 업무 리소스로 이어지며, 이를 해결하기 위해 사내 AI 봇을 기획하고 만들게 되었다.
n8n이란 무엇인가?
Make 와 Zapier 같이 다양한 애플리케이션 간의 자동화를 no code로 도와주는 서비스 이다.
하지만, 위 툴들과 다르게 n8n이 요즘 각광을 받는 이유는 한 가지다.
바로 '셀프호스팅'을 제공한다. 즉, 내가 DevOps 지식만 있다면, 거의 무료로 자동화 시스템을 구축 할 수 있다는 말이다.
왜 RAG를 기반으로 하는 AI 챗봇으로 기획했나?
처음에 기획 했을때는 RAG가 아닌 단순히 AI Agent 노드로 제작 하였다.
노션에 올라가 있는 데이터가 많지도 않고, 따라서 성능이슈는 없을 것으로 예상했다.
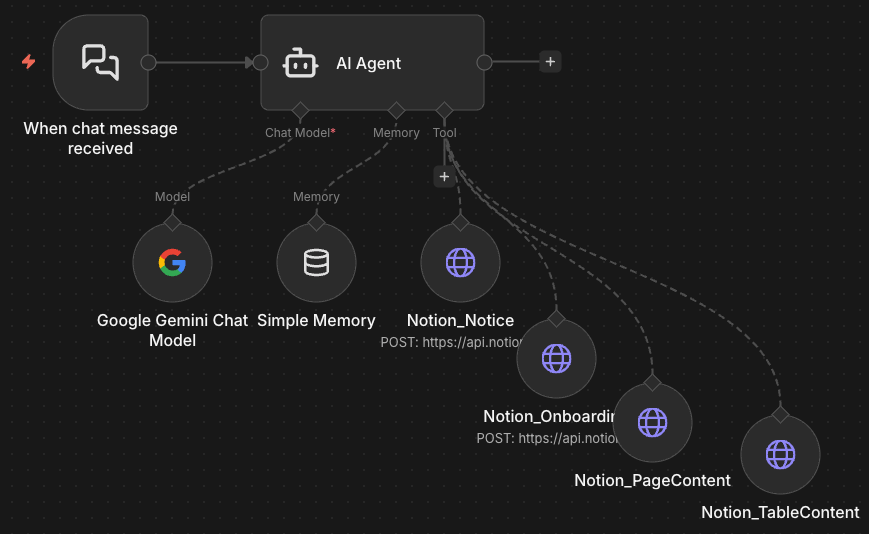
AI Agent 독립사용 워크플로우 이미지
문제점: 노션 블록 누락 및 성능이슈
- 노션 페이지의 블록 누락 이슈
이번에 정확히 알게된 사실인데, 노션 데이터를 json으로 받게 되면, 페이지에 그냥 있는 text의 depth와 콜아웃, 토글, 표 등의 블록의 depth가 달라 데이터를 읽어오는 과정에서 이를 모두 고려해야 한다.
그래서 위 이미지를 보면 "데이터베이스 Get -> 각각 페이지 ID 추출 -> 각 페이지 Get -> 각 페이지에서 블록 추출" 하는 로직이 필요하다.
이 과정에서 난 모든 블록을 고려하는 것은 포기하고 표와 텍스트만 가져오기로 했다.
위 문제는 Notion Node를 이용하면 비교적 간단하게 해결이 될 수도 있지만 일일히 설정 해야 하는 것은 변함이 없다. - 성능 이슈(속도)
노션에서 데이터를 조회하는 노드가 4개가 있고, 이렇게 하여도 사용자가 채팅을 입력할 때마다 전체 노션 데이터를 실시간으로 조회해야 한다.
데이터가 적을 때는 큰 문제가 없었지만, 페이지가 늘어날수록 응답 지연이 눈에 띄게 증가했다.
매 요청마다 Notion API를 여러 번 호출하는 구조 자체가 근본적인 병목이었다.
개선된 아키텍처: RAG + Qdrant Vector Store
위 두 가지 문제를 해결하기 위해 아키텍처를 완전히 재설계했다.
핵심 아이디어
노션 데이터를 매 요청마다 가져오는 대신, 주기적으로 벡터 DB에 임베딩해두고 AI Agent가 이를 Tool로 검색하는 방식으로 전환했다.
최종 워크플로우 구성
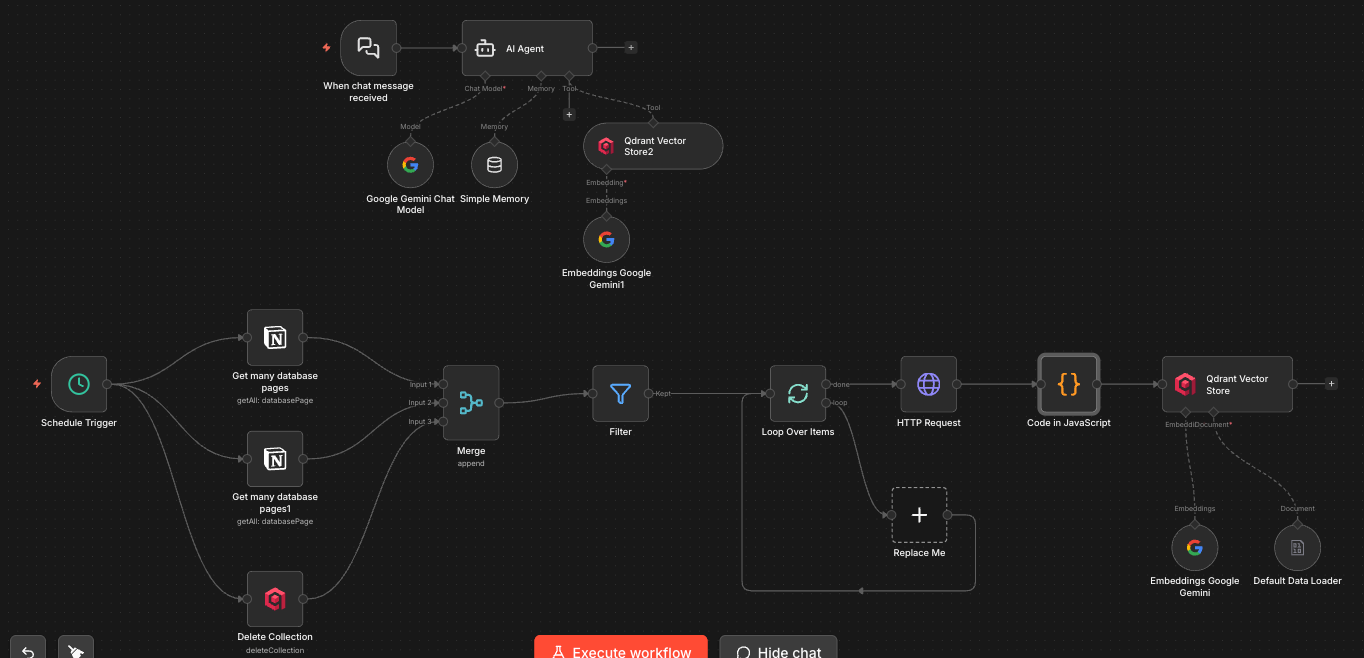
전체 플로우
워크플로우는 크게 두 개의 독립적인 플로우로 나뉜다.
1. 데이터 수집 플로우 (Schedule Trigger 기반)
Schedule Trigger
→ Get many database pages (DB1)
→ Get many database pages1 (DB2)
→ Delete Collection (Qdrant 컬렉션 초기화)
→ Merge (append)
→ Filter
→ Loop Over Items
→ HTTP Request (Notion 페이지 본문 조회)
→ Code in JavaScript (텍스트 가공)
→ Qdrant Vector Store (임베딩 저장)
← Embeddings Google Gemini
← Default Data Loader
주요 포인트:
Schedule Trigger로 주기적(예: 매일 새벽)으로 실행된다.- 실행 시작 시
Delete Collection으로 기존 벡터 데이터를 전부 삭제 후 재적재한다. 이렇게 하면 노션에서 수정/삭제된 내용이 자동으로 반영된다. - 여러 노션 DB를
Merge (append)로 합쳐 단일 파이프라인으로 처리한다. Filter로 불필요한 페이지(미완성, 비공개 등)를 걸러낸다.Loop Over Items로 각 페이지를 순회하며 Notion API(HTTP Request)로 본문을 가져온다.Code in JavaScript로 블록 타입별 텍스트 추출 및 포맷팅을 처리한다.- 최종적으로
Qdrant Vector Store에 Google Gemini 임베딩과 함께 저장한다.
2. 채팅 플로우 (When chat message received 기반)
When chat message received
→ AI Agent
← Google Gemini Chat Model
← Simple Memory
← Qdrant Vector Store2 (Tool)
← Embeddings Google Gemini1
주요 포인트:
- 사용자 메시지를 받으면 AI Agent가 동작한다.
Qdrant Vector Store를 Tool로 연결하여, Agent가 필요할 때만 벡터 검색을 수행한다.Simple Memory로 대화 히스토리를 유지해 멀티턴 대화가 가능하다.- Notion API 호출이 전혀 없으므로 응답 속도가 획기적으로 빨라진다.
개선 전/후 비교
항목
개선 전 (AI Agent 단독)
개선 후 (RAG + Qdrant)
데이터 조회 시점
매 요청마다 실시간
주기적 사전 적재
응답 속도
느림 (Notion API 다중 호출)
빠름 (벡터 검색)
블록 누락
있음
HTTP Request로 직접 조회하여 감소
최신 데이터 반영
즉시
스케줄 주기에 따라 반영
비용
Notion API 호출 多
임베딩 비용 발생 (저렴)
구현 시 주요 고려사항
Notion HTTP Request로 블록 직접 조회
Notion Node 대신 HTTP Request를 사용한 이유는 유연성 때문이다. Notion API의 /blocks/{block_id}/children 엔드포인트를 직접 호출하면 블록 타입을 코드로 직접 핸들링할 수 있다.
JavaScript 코드 노드에서의 텍스트 추출
// 블록 타입별 텍스트 추출 예시
const items = $input.all();
const results = [];
for (const item of items) {
// HTTP Response body 추출
const body = item.json.body ?? item.json;
// pageId와 pageTitle은 Loop의 현재 아이템에서 가져오기
// (Loop Over Items가 넘겨준 원본 페이지 정보)
const pageId = item.json.pageId
?? item.json.id
?? body?.results?.[0]?.parent?.page_id
?? "";
const pageTitle = item.json.pageTitle ?? item.json.title ?? "Untitled";
const lastEdited = item.json.last_edited_time ?? "";
// block results 배열 추출
const blocks = body?.results ?? [];
// 각 블록에서 텍스트 추출
const textParts = [];
for (const block of blocks) {
const type = block.type;
const blockData = block[type];
if (!blockData) continue;
// rich_text 배열이 있는 블록 타입들 처리
const richText = blockData.rich_text ?? [];
const blockText = richText
.map(rt => rt.plain_text ?? rt.text?.content ?? "")
.join("");
if (blockText.trim()) {
// 헤딩 타입은 앞에 마크다운 표시
if (type === "heading_1") textParts.push(`# ${blockText}`);
else if (type === "heading_2") textParts.push(`## ${blockText}`);
else if (type === "heading_3") textParts.push(`### ${blockText}`);
else if (type === "bulleted_list_item") textParts.push(`• ${blockText}`);
else if (type === "numbered_list_item") textParts.push(`- ${blockText}`);
else textParts.push(blockText);
}
}
const bodyText = textParts.join("\n");
results.push({
json: {
text: `제목: ${pageTitle}\n\n[본문]\n${bodyText}`,
metadata: {
pageId,
pageTitle,
chunkIndex: 0,
source: "notion",
lastEdited,
}
}
});
}
return results;
Qdrant 컬렉션 초기화 전략
매 실행마다 컬렉션을 삭제 후 재생성하는 방식은 단순하지만 효과적이다. 업데이트/삭제 추적 로직 없이도 항상 노션과 동기화된 상태를 유지할 수 있다. 데이터 양이 많아지면 upsert 방식으로 전환을 고려할 수 있다.
마무리
n8n + Notion + Qdrant + Google Gemini 조합으로 사내 AI 챗봇을 구축한 결과, 인사팀의 반복 문의 대응 부담을 크게 줄일 수 있었다. 특히 RAG 아키텍처 도입 후 응답 품질과 속도 모두 만족스러운 수준으로 개선되었다.
셀프호스팅 n8n의 가장 큰 장점은 API 키와 데이터가 외부로 나가지 않는다는 점이다. 사내 민감 정보를 다루는 HR 봇에는 이 점이 특히 중요했다.