Text-to-SQL: "매출 지난달이랑 비교해줘" 한 마디로 BigQuery의 데이터 분석 및 리포트 작성
TL;DR — SQL을 몰라도 된다. 자연어로 분석을 요청하면 AI가 SQL을 자동 생성하고, BigQuery에 직접 쿼리를 날려 결과를 돌려주는 Text-to-SQL 분석 시스템을 구축했다. 핵심은 Claude Projects + BigQuery MCP + 커스텀 Analytics Skill의 조합이다.
페인포인트: 분석은 필요한데, 매번 개발자한테 물어봐야 했다
데이터가 쌓이면 질문이 생긴다.
- "이번 달 채널별 매출 비중이 어떻게 돼?"
- "지난 3개월 평균이랑 비교하면 어때?"
- "해외 환자 유입이 전년 대비 얼마나 늘었어?"
이 질문들의 공통점은 답이 데이터베이스 안에 있다는 것이다. 그런데 문제가 있었다.
데이터를 꺼내려면 SQL을 알아야 한다.
우리팀은 분석 요청이 생길 때마다 업무 리소스가 발생했다. 요청 → 전달 → 쿼리 작성 → 결과 전달의 사이클이 반복됐고, 특히 복잡한 분석을 요청하는 경우 쿼리 작성 시간이 길어졌다.
우리팀은 더 게을러지기 위해 이 Claude Project를 만들었다.
왜 Text-to-SQL인가
Text-to-SQL은 자연어(Natural Language) 질의를 SQL로 자동 변환하는 기술이다. NL2SQL이라고도 부른다.
개념 자체는 오래됐지만, LLM(대형 언어 모델)의 등장으로 실용적인 수준에 도달했다. 특히 테이블 스키마와 비즈니스 컨텍스트를 함께 제공하면, 모델이 도메인에 맞는 정확한 SQL을 생성할 수 있게 됐다.
이 방식을 선택한 이유는 단순하다.
- 별도 UI 개발 없이 구현 가능
- 기존 BigQuery 인프라를 그대로 활용
- 비개발자도 즉시 사용 가능
- 질문의 형태와 깊이에 제한이 없음
시스템 구조
세 가지 컴포넌트가 핵심이다.
컴포넌트 1 — BigQuery MCP
MCP(Model Context Protocol)는 AI 모델이 외부 서비스와 직접 통신할 수 있게 해주는 프로토콜이다. BigQuery MCP를 연결하면 Claude가 SQL을 생성하는 것에 그치지 않고, BigQuery에 직접 쿼리를 실행하고 결과를 받아올 수 있다.
기존 Text-to-SQL의 한계는 "SQL을 생성해주면 사람이 직접 실행해야 한다"는 것이었다. MCP는 이 단계를 없앤다. 자연어 질의부터 분석 결과까지 중간에 사람이 개입하지 않아도 된다.
컴포넌트 2 — tu-analytics Skill
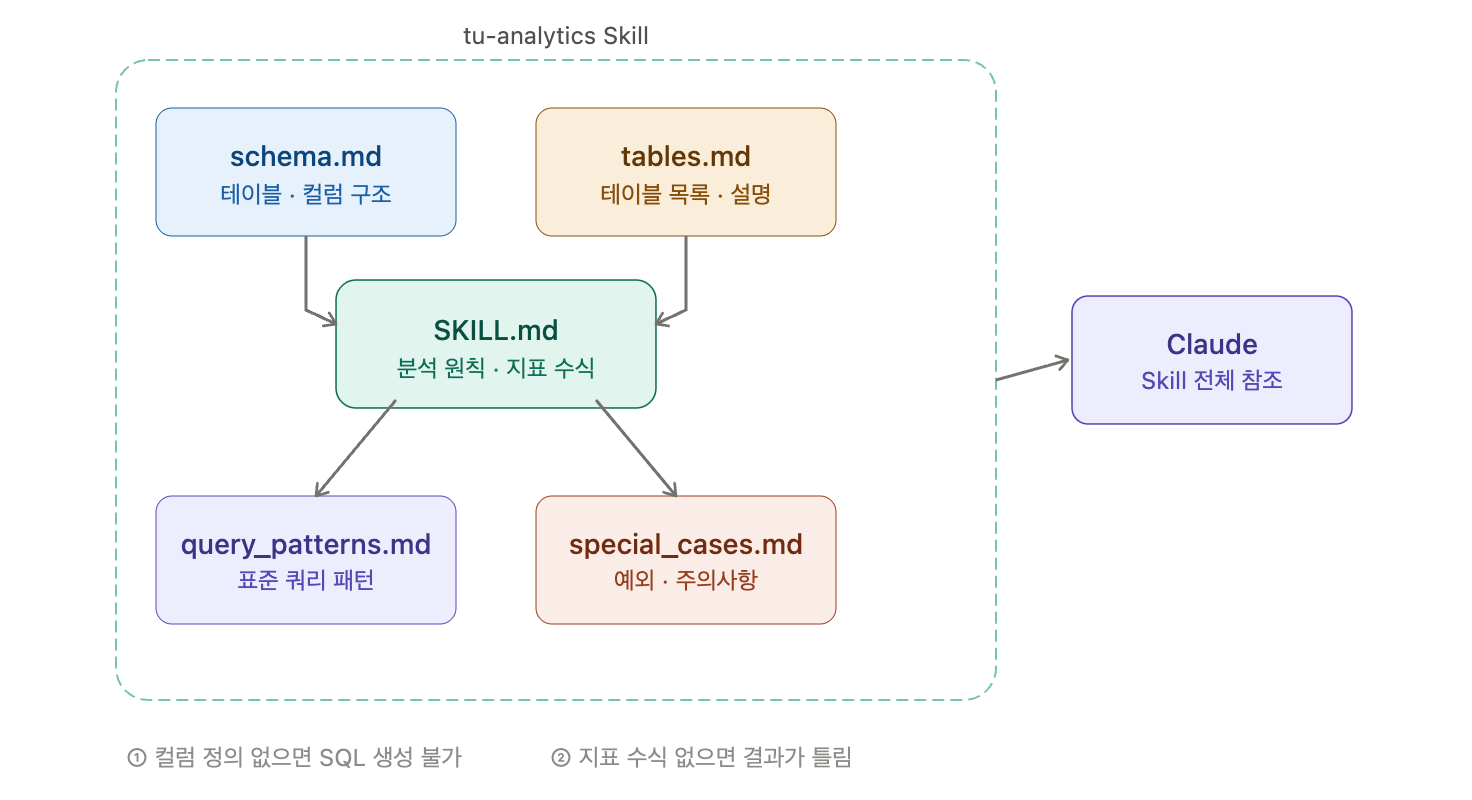
Claude의 Skill은 특정 도메인에 대한 지식과 규칙을 패키징한 컨텍스트 파일이다. tu-analytics Skill에는 다음이 담겨 있다.
스키마 정보 (schema.md) 테이블 구조, 컬럼 설명, 데이터 타입. Claude가 올바른 SQL을 생성하려면 테이블이 어떻게 생겼는지 알아야 한다.
지표 정의 (tables.md / 분석 지침) 단순한 컬럼 설명을 넘어, 비즈니스 지표의 정확한 계산식을 정의한다. 예를 들어 "객단가"는 단순 평균이 아니라 특정 필터 조건을 만족하는 행만 포함해야 한다. 이런 규칙이 없으면 SQL은 실행되지만 결과가 틀린다.
쿼리 패턴 (query_patterns.md) 자주 사용하는 분석 패턴을 템플릿화했다. 영업일 기준 동기 비교, 국내/해외 분리 집계, 누적 영업일 필터링 등 반복되는 로직을 표준화해두면 매번 처음부터 만들지 않아도 된다.
특수 케이스 (special_cases.md) 데이터의 예외 상황과 주의사항. 예를 들어 특정 컬럼에 NULL이 들어오는 경우 어떻게 처리해야 하는지, 중복 제거는 어떤 기준으로 하는지 등이 명시돼 있다.
이 Skill이 없으면 Claude는 일반적인 SQL은 만들 수 있지만, 이 데이터베이스의 맥락에 맞는 정확한 SQL은 만들기 어렵다.
컴포넌트 3 — Claude Projects
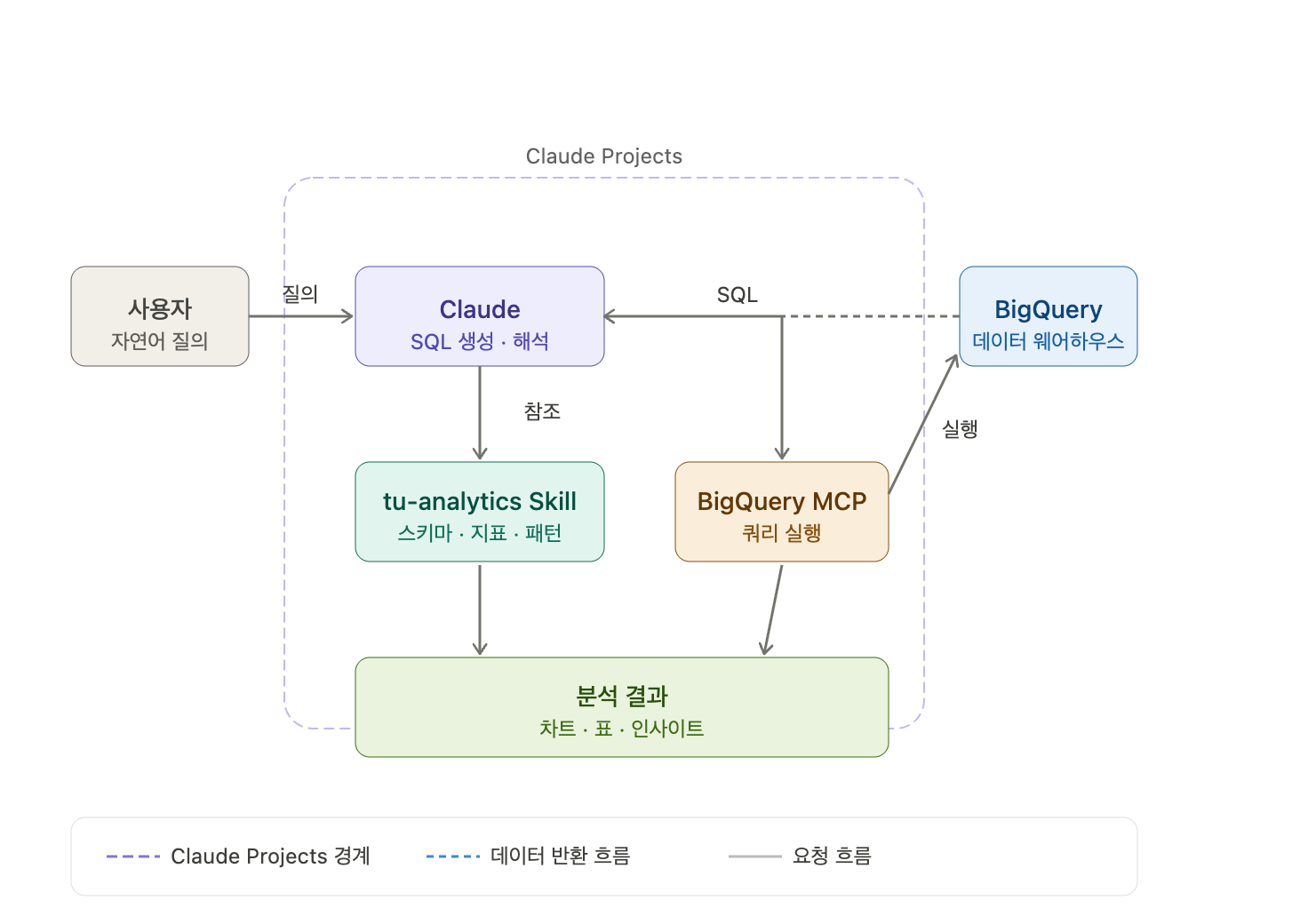
Claude Projects는 특정 프로젝트에 대한 지식과 설정을 지속적으로 유지할 수 있는 환경이다. tu-analytics Skill을 프로젝트에 연결해두면, 매번 컨텍스트를 다시 설명하지 않아도 된다.
대화가 길어지거나 세션이 바뀌어도 테이블 구조, 지표 정의, 분석 원칙이 유지된다.
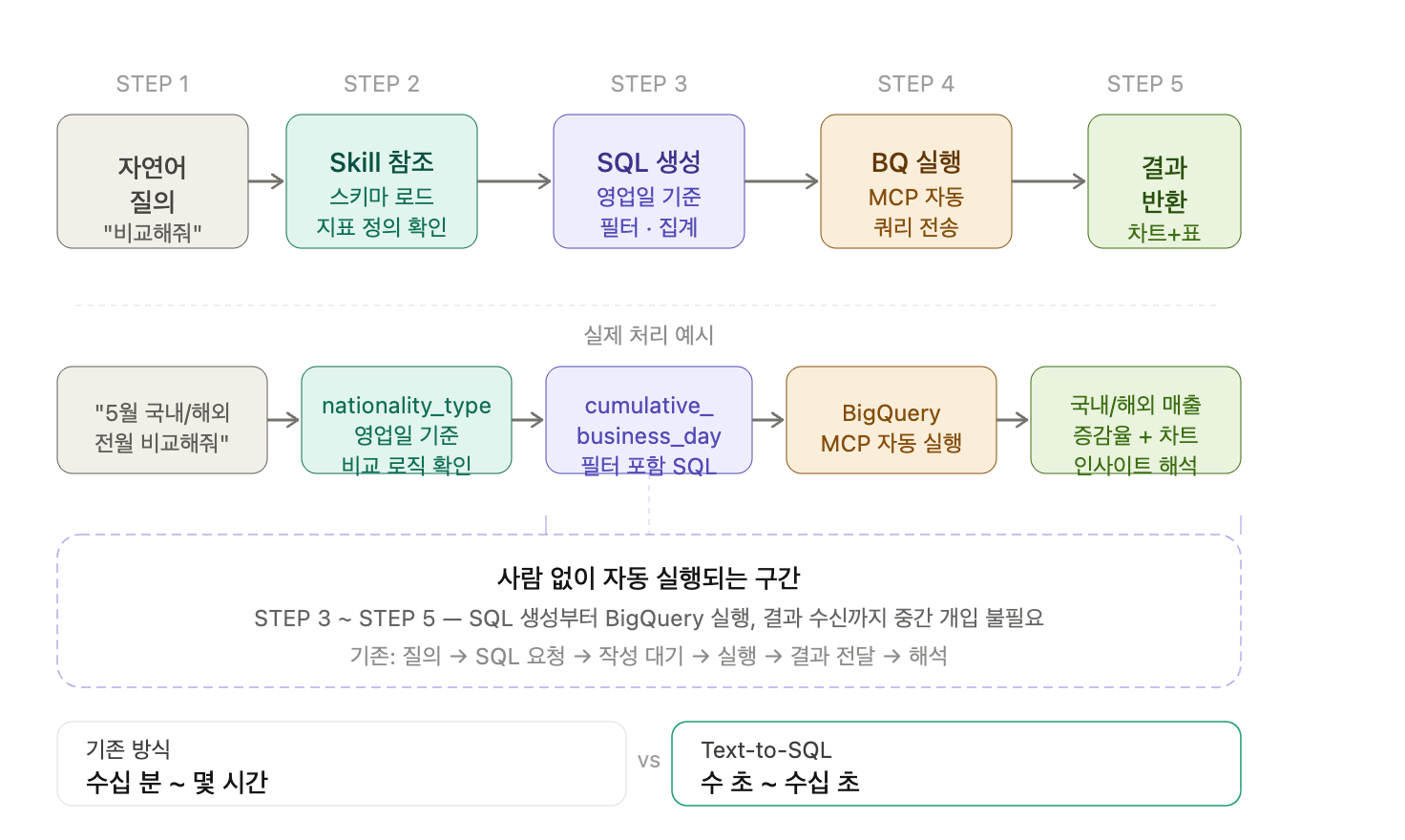
실제로 어떻게 작동하나
질의 예시:
"5월 국내/해외 매출 전월 동기 대비 비교해줘"
내부 처리 과정:
- Claude가 Skill을 참조해 관련 테이블과 컬럼을 파악
- "전월 동기"의 의미를 영업일 기준으로 해석 (달력 날짜 기준이 아님)
- 국내/해외 분리 집계 쿼리 생성 (
nationality_type기준) - BigQuery MCP로 쿼리 실행
- 결과 반환 → 증감 계산 + 시각화 + 인사이트 해석
핵심은 3번과 4번 사이에 사람이 없다는 것이다.

결과 리포트 예시
설계에서 가장 신경 쓴 것
지표 정의의 명확성
"매출이 얼마야?"라는 질문은 단순해 보이지만, 어떤 컬럼을 쓰느냐에 따라 숫자가 달라진다. 고객납부액인지, 매출귀속액인지, 세금 포함/제외인지. 이 정의가 Skill에 명확하게 박혀 있어야 일관된 결과가 나온다.
수식 하나하나를 명문화하는 작업이 시스템 구축보다 더 시간이 걸렸다.
비교 기준의 표준화
"전월 대비"를 단순 날짜 수로 비교하면 안 된다. 영업일 수가 다른 달을 날짜 기준으로 비교하면 오해를 부른다. 이 시스템은 영업일 기준 동기 비교를 표준으로 정의하고, 모든 기간 비교에 이 원칙을 적용한다.
당월 / 전월 동기 / 직전 3개월 평균 / 전년 동기 — 네 가지 비교 기준을 항상 함께 제공하는 것도 규칙으로 정해뒀다.
결과물 형식의 일관성
분석 결과가 매번 다른 형태로 나오면 보는 사람이 불편하다. 스코어카드 → 차트 → 표 요약 → 인사이트의 순서를 표준화하고, 증감 표기 방식(▲/▼, 색상 코드)도 규칙으로 정의했다.
한계와 주의할 점
완벽하지 않다. LLM 기반 SQL 생성은 복잡한 조건이 중첩될수록 오류 가능성이 높아진다. 이 때문에 중요한 분석은 결과를 검증하는 습관이 필요하다.
컨텍스트 품질이 전부다. Skill에 정의된 스키마와 지표가 부정확하면 SQL도 틀린다. "쓰레기가 들어가면 쓰레기가 나온다(GIGO)"는 여기서도 그대로 적용된다. 초기 Skill 작성과 지속적인 업데이트가 시스템 품질을 결정한다.
MCP는 현재 사용자 단위 인증이다. BigQuery MCP는 개인 인증 기반으로 동작한다. 조직 전체가 동일한 연결을 공유하는 구조가 아니므로, 팀 단위 배포 시에는 이 점을 고려해야 한다.
결과
SQL을 모르는 팀원도 분석 질문을 직접 던질 수 있게 됐다. 분석 요청 → 결과 확인의 사이클이 대폭 줄었고, "물어보기 애매해서 참던" 질문들이 올라오기 시작했다.
데이터 민주화라는 말이 있다. 데이터를 다루는 기술이 없어도 데이터에서 인사이트를 얻을 수 있게 되는 것. Text-to-SQL이 그 방향으로 한 걸음 가까워지게 해준 기술이라고 생각한다.
사용 기술: Claude Projects, BigQuery MCP, Model Context Protocol (MCP), Google BigQuery
관련 키워드: Text-to-SQL, NL2SQL, Conversational Analytics, AI Analytics, Data Democratization